
分布式存储系统Megastore,大规模分布式系统的监控基础架构Dapper
分布式存储系统Megastore
设计目标及方案选择
设计一种介于传统的关系型数据库和NoSQL之间的存储技术,尽可能达到高可用性和高可扩展性的统一。
方法1:针对可用性的要求,实现了一个同步的、容错的、适合远距离传输的复制机制。
方法2:针对可扩展性的要求,将整个大的数据分割成很多小的数据分区,每个数据分区连同它自身的日志存放在NoSQL数据库中,具体来说就是存放在Bigtable中。
数据的分区和复制
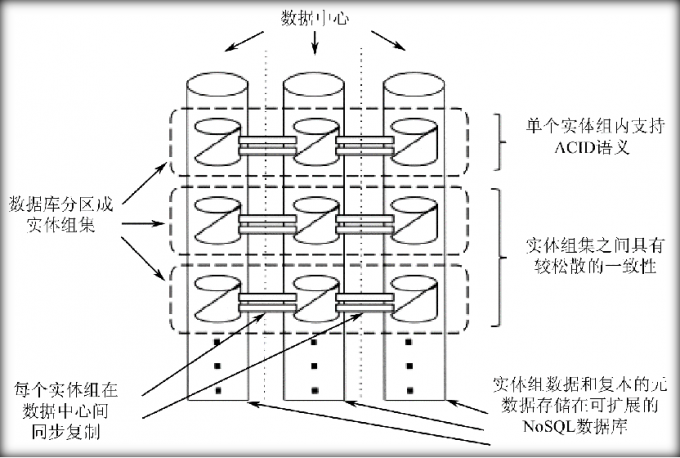
在Megastore中,这些小的数据分区被称为实体组集(Entity Groups)。
每个实体组集包含若干的实体组(Entity Group,相当于分区中表的概念)。
一个实体组中包含很多的实体(Entity,相当于表中记录的概念)。
Megastore数据模型
传统的关系型数据库不合适的三个原因
传统的关系型数据库是通过连接(Join)来满足用户的需求的,但是就Megastore而言,这种数据模型是不合适的,主要有以下三个原因:
- 对于高负载的交互式应用来说,可预期的性能提升要比使用一种代价高昂的查询语言所带来的好处多
- Megastore所面对的应用是读远多于写,因此好的选择是将读操作所需要做的工作尽可能地转移到写操作上
- 在Bigtable这样的键/值存储系统中存储和查询级联数据(Hierarchical Data)是很方便的
细粒度控制的数据模型和模式语言(Google团队设计的Megastore数据模型)
同关系型数据库一样,Megastore的数据模型是在模式(schema)中定义的且是强类型的(strongly typed)
每个模式都由一系列的表(tables)构成,表又包含有一系列的实体(entities),每实体中包含一系列属性(properties)
属性是命名的且具有类型,这些类型包括字符型(strings)、数字类型(numbers)或者Google的Protocol Buffers。
照片共享服务数据模型实例
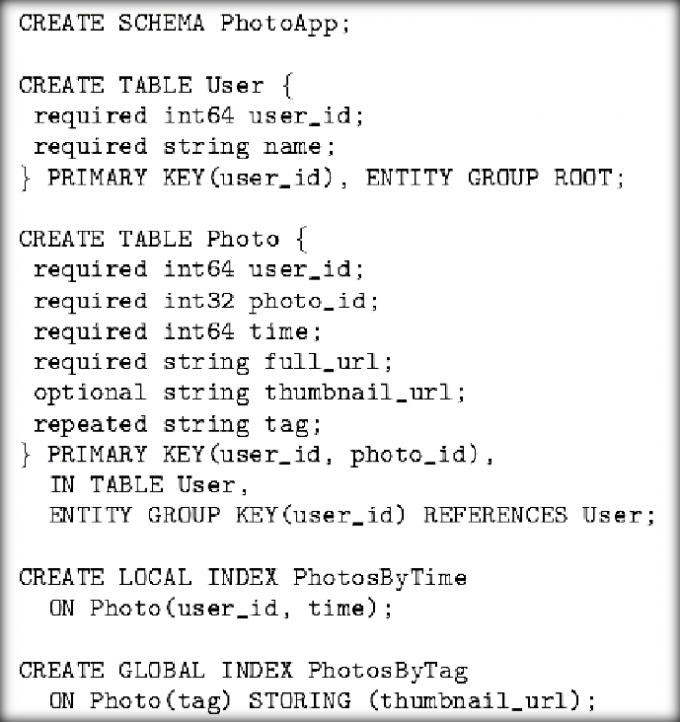
- 表Photo就是一个子表,因为它声明了一个外键
- User则是一个根表
- 一个Megastore实例中可以有若干个不同的根表,表示不同类型的实体组集
- 三种不同属性设置,既有必须的(如user_id),也有可选的(如thumbnail_url)
- Photo中的可重复类型的tag属性
Megastore索引
主要索引:
- 局部索引:定义在单个实体组中,作用域仅限于单个实体组( 如PhotosByTime )
- 全局索引:可以横跨多个实体组集进行数据读取操作( 如PhotosByTag )
额外索引:
- STORING子句(STORING Clause)
- 可重复的索引(Repeated Indexes)
- 内联索引(Inline Indexes)
Bigtable中存储情况
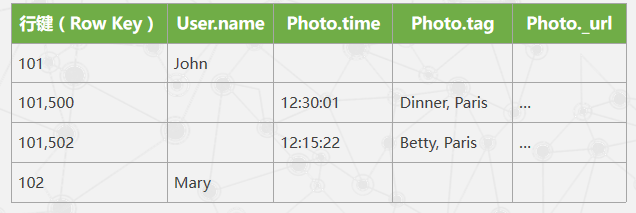
Bigtable的列名实际上是表名和属性名结合在一起得到,不同表中实体可存储在同一个Bigtable行中
Megastore中的事务及并发控制
Megastore提供的三种读
- current:总是在单个实体组中完成
- snapshot:总是在单个实体组中完成;系统取出已知的最后一个完整提交的事务的时间戳,接着从这个位置读数据
- inconsistent:忽略日志的状态直接读取最新的值
Megastore中的事务机制
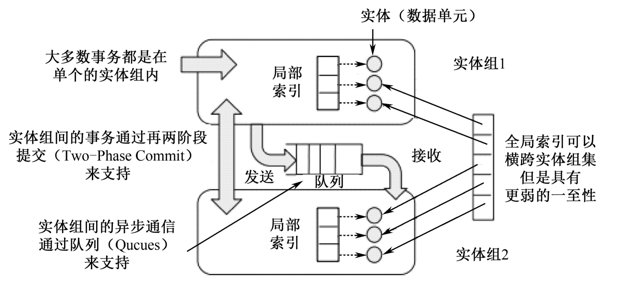
Megastore基本架构
在Megastore中共有三种副本:
- 完整副本(Full Replica)
- 见证者副本(Witness Replica)
- 只读副本(Read-only Replica)
快速读与快速写
快速读:
- 利用本地读取实现快速读,带来更好的用户体验及更低的延迟
- 关键是保证选择的副本上数据是最新的
- 协调者是一个服务,该服务分布在每个副本的数据中心里面。它的主要作用就是跟踪一个实体组集合
- 协调者的状态是由写算法来保证
快速写:
- 如果一次写成功,那么下一次写的时候就跳过准备过程,直接进入接受阶段
- Megastore没有使用专门的主服务器,而是使用leaders
- leader主要是来裁决哪个写入的值可以获取0号提议
- 客户端、网络及Bigtable的故障都会导致一个写操作处于不确定的状态
核心技术——复制
每个副本都存有记录所有更新的数据。
Megastore允许副本不按顺序接受日志,这些日志将独立的存储在Bigtable中。
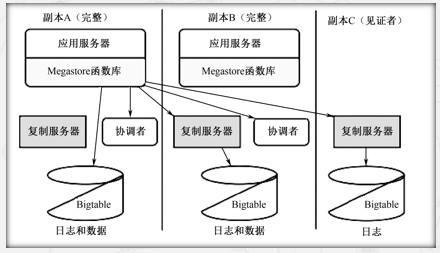
数据读取
本地查询→发现位置→追赶→验证→查询数据
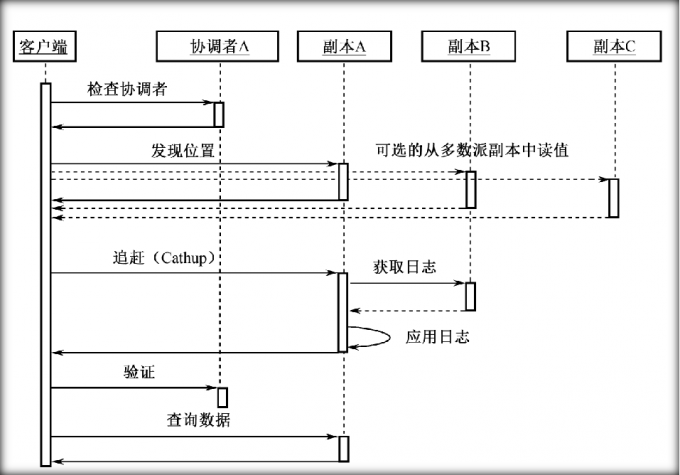
数据写入
接受leader→准备→接受→失效→生效
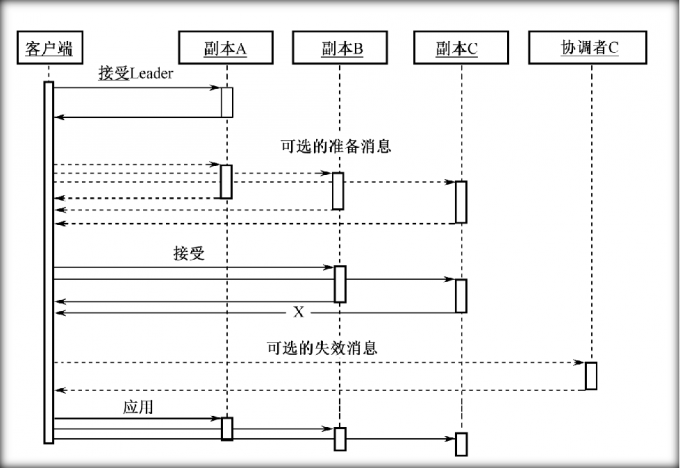
协调者的可用性
- 协调者在系统中是比较重要的——协调者的进程运行在每个数据中心。每次的写操作中都要涉及协调者,因此协调者的故障将会导致系统的不可用
- Megastore使用了Chubby锁服务,为了处理请求,一个协调者必须持有多数锁。一旦因为出现问题导致它丢失了大部分锁,协调者就会恢复到一个默认保守状态
- 除了可用性问题,对于协调者的读写协议必须满足一系列的竞争条件
产品性能及控制措施
可用性的分布情况
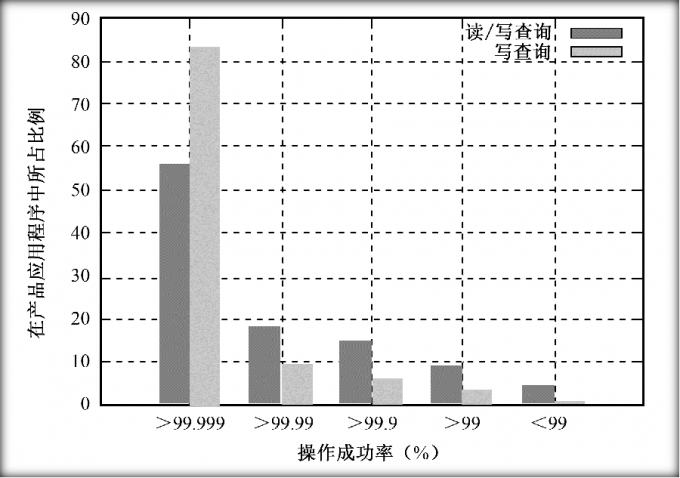
Megastore在Google中已经部署和使用了若干年,有超过100个产品使用Megastore作为其存储系统
从图中可以看出,绝大多数产品具有极高的可用性(>99.999%)。这表明Megastore系统的设计是非常成功的,基本达到了预期目标
产品延迟情况的分布
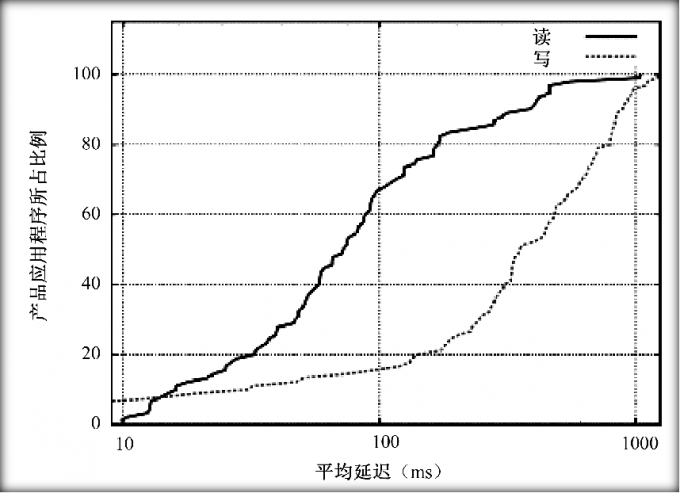
应用程序的平均读取延迟在万分之一毫秒之内,平均写入延迟在100至400毫秒之间
避免Megastore的性能下降,可采取以下三种应对方法:
- 重新选择路由使客户端绕开出现问题的副本
- 将出现问题副本上的协调者禁用,确保问题的影响降至最小。
- 禁用整个副本
大规模分布式系统的监控基础架构Dapper
基本设计目标
两个基本要求
- 广泛可部署性(Ubiquitous Deployment)
- 设计出的监控系统应当能够对尽可能多的Google服务进行监控
- 不间断的监控
- Google的服务是全天候的,如果不能对Google的后台同样进行全天候的监控很可能会错过某些无法再现的关键性故障
三个基本设计目标
- 低开销:这个是广泛可部署性的必然要求。监控系统的开销越低,对于原系统的影响就越小,系统的开发人员也就越愿意接受这个监控系统。
- 对应用层透明:监控系统对程序员应当是不可见的。如果监控系统的使用需要程序开发人员对其底层的一些细节进行调整才能正常工作的话,这个监控系统肯定不是一个完善的监控系统。
- 可扩展性:Google的服务增长速度是惊人的,设计出的系统至少在未来几年里要能够满足Google服务和集群的需求。
Dapper监控系统简介
在监控系统中记录下所有这些消息不难,如何将这些消息记录同特定的请求(本例中的X)关联起来才是分布式监控系统设计中需要解决的关键性问题之一。
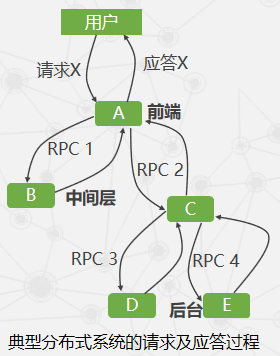
Dapper监控系统的三个基本概念
- 监控树(Trace Tree):一个同特定事件相关的所有消息
- 区间(Span):区间实际上就是一条记录
- 注释(Annotation):注释主要用来辅助推断区间关系,也可以包含一些自定义的内容
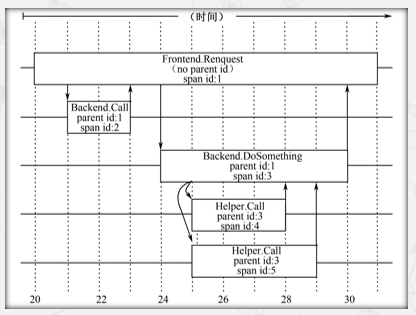
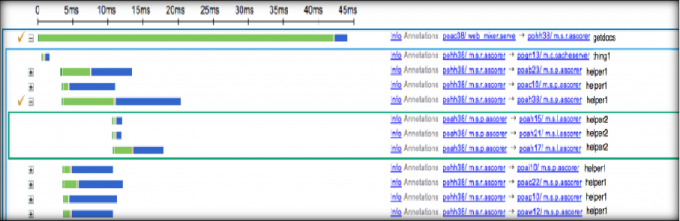
区间Helper.Call的详细信息
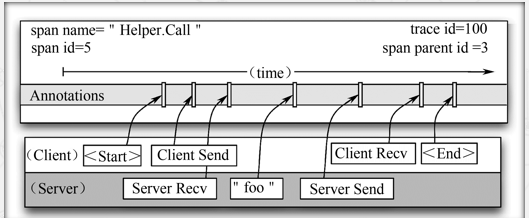
区间包含了来自客户端的注释信息:“
监控信息的汇总
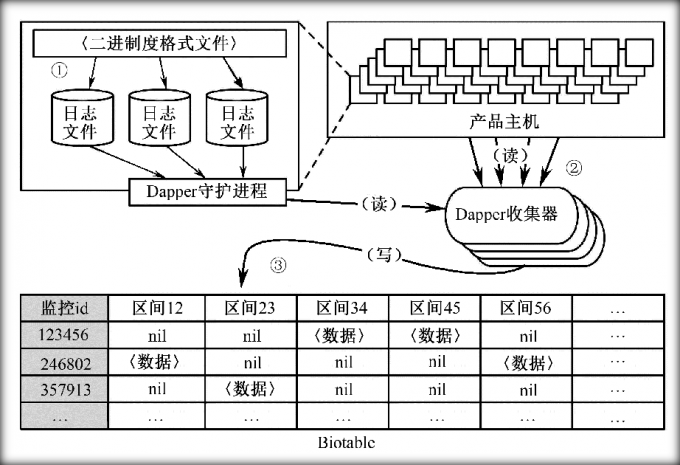
- 将区间的数据写入到本地的日志文件
- 所有机器上的本地日志文件汇集
- 汇集后的数据写入到Bigtable存储库中
关键性技术
轻量级核心功能库
小规模库:
- 通用线程(Ubiquitous Threading)
- 控制流(Control Flow)
- RPC代码库(RPC Library Code)
- 最关键的代码基础是基本RPC、线程和控制流函数库的实现
- 主要功能是实现区间创建、抽样和在本地磁盘上记录日志。
- 将复杂的功能实现限制在一个轻量级的核心功能库中保证了Dapper的监控过程基本对应用层透明。
二次抽样技术
利用二次抽样技术成功地解决了低开销及广泛可部署性的问题。
第一次抽样:
实践中,设计人员发现当抽样率低至1/1024时也能够产生足够多的有效监控数据,即在1024个请求中抽取1个进行监控也是可行的,从而可以捕获有效数据
第二次抽样:
发生在数据写入Bigtable前,具体方法是将监控id散列成一个标量z(0≤z≤1),如果某个区间的z小于事先定义好的汇总抽样系数,则保留这个区间并将它写入Bigtable,否则丢弃
常用Dapper工具
Dapper存储API
Dapper的“存储API”简称为 DAPI,提供了对分散在区域Dapper存储库(DEPOTS)的监控记录的直接访问。一般有以下三种方式访问这些记录。
- 通过监控id访问(Access by Trace id):利用全局唯一的监控id直接访问所需的监控数据
- 块访问(Bulk Access):借助MapReduce对数以十亿计的Dapper监控数据的并行访问
- 索引访问(Indexed Access):Dapper存储库支持单索引(Single Index)
Dapper用户界面
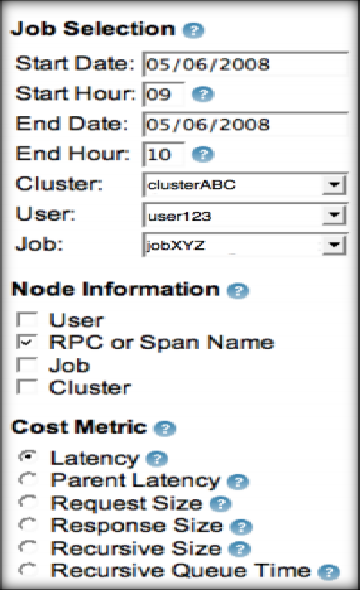
- 选择监控对象
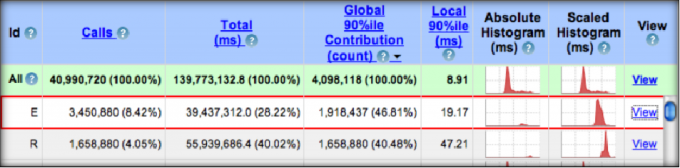
- 用户对这些执行模式进行排序并选择查看更多细节
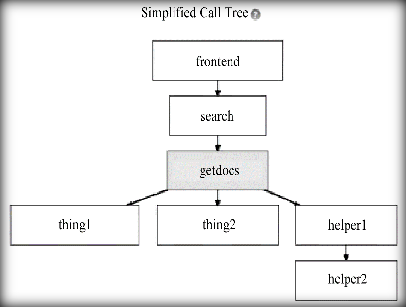
- 分布式执行模式图形化描述呈现给用户
- 根据最初选择的开销度量标准,Dapper以频度直方图的形式将步骤3中选中的执行模式的开销分布展示出来
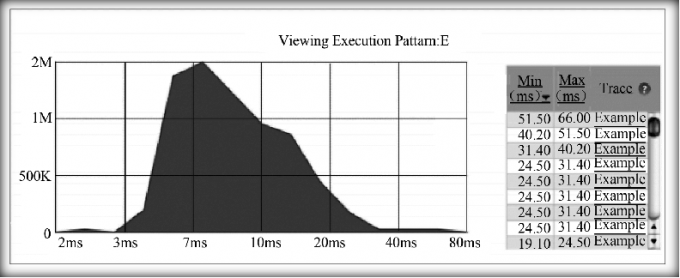
- 用户选择了某个监控样例后,就会进入所谓的监控审查视图 (Trace Inspection View)
Dapper使用经验
- 新服务部署中Dapper的使用:利用Dapper对系统延迟情况进行一系列的跟踪,进而发现存在的问题
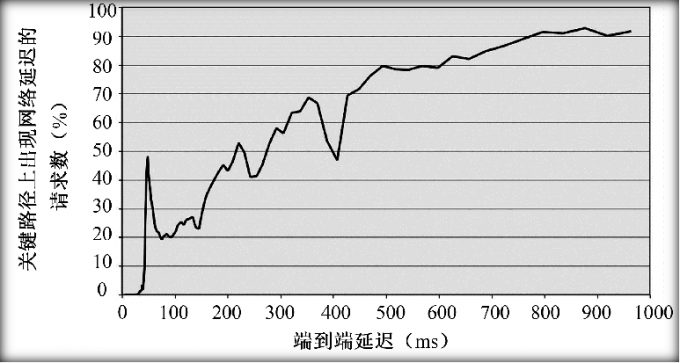
- 定位长尾延迟(Addressing Long Tail Latency):端到端性能和关键路径上的网络延迟有着极大的关系
- 推断服务间的依存关系(Inferring Service Dependencies):Google的“服务依存关系”项目使用监控注释和DPAI的MapReduce接口实现了服务依存关系确定的自动化
- 确定不同服务的网络使用情况:利用Dapper平台构建了一个连续不断更新的控制台,用来显示内部集群网络通信中最活跃的应用层终端
- 分层的共享式存储系统:没有Dapper之类的工具的情况下对于这种共享式服务资源的争用也同样难以调试
- 利用Dapper进行“火拼”(Firefighting with Dapper):Dapper用户可以通过和Dapper守护进程的直接通信,将所需的最新数据汇总在一起